Under the hood (part 2): the evolution of TradeSpeed's data extraction and checks
- Aisling Mullins

- May 30
- 9 min read
The expertise behind a TradeSpeed check is only half of the story. The technology and architecture beneath it is the other half.
By Aisling Mullins, Chief Product Officer

Last month, we sat down with Gary Collyer to look at the craft behind TradeSpeed's document examination checks: how a career's worth of UCP and ISBP knowledge becomes the logic of a system a bank can trust. In other words, how we translate decades of letter of credit (LC) examination experience into structured checks, discrepancy wordings, and rules that artificial intelligence (AI) can reason against.
This month we step into the room next door: the engine room. The architecture beneath those checks and how the technology that runs them has changed across four years, and what each generation and update has added to TradeSpeed's capabilities.
If you've read part 1 of our "Under the hood" series, you know how much work and how many hours go into the development of every single check. But underlying all of this work, our team has one key question that guides all of our check development: How do we make every automated check we develop behave like a senior examiner would? Depending on the check, this might be as simple as matching a pattern or data point between documents' pages, or as complex as reasoning across multiple documents the way someone with twenty-plus years in an LC department would.
While the end-goal of our product and tech team is to create a platform so smooth that users don't need to worry about how this is done, it is still important for us to share what is under the hood. Because the requirements each check has are what define the architecture and technology that needs to be used for it, which in turn informs what is currently possible and at what level of accuracy.
Some of the checks TradeSpeed runs today would have been impossible four years ago. Not because we didn't know the rules or questions to be asked. But at the time the existing technology couldn't yet support what we, and primarily our customers, expected those checks to do. Or at least not at the quality or accuracy level we were willing to commit to.
What follows is the unsung half of the check development story. The engineering work that keeps the product moving forward, implementing the frontier technologies available and transforming deep human knowledge into a system that examiners and operations teams can actually rely on.
There were four key moments where the technology underneath our checks shifted. Each one opened a door the previous architecture couldn't, while building on top of what was there before and enhancing our checks engine. This coexistence of technologies is important enough that I'll come back to it at the end. Let's dive into these four check eras.

2022: Custom machine learning and the labelled-data era
When we started building TradeSpeed's check engine four years ago, the data layer underneath was custom machine learning. Optical character recognition (OCR) to lift text from documents, then supervised models trained per document type to recognise what each field meant. Bill of lading. Commercial invoice. Packing list. Insurance certificate, and so on. Each model trained on its own corpus, often with up to thousands annotated examples. The extracted data flowed into a rule engine, which applied deterministic "if-then" logic to check it against the credit and against the UCP and ISBP rules.

It worked. This was the first real automated check capability for documentary trade, and every check ran fully traceable, with every discrepancy under our control and every result reproducible. For a bank operations team, the built-in logic and traceability were what made the system credible.
The limit we faced during this time was granularity. The custom models TradeSpeed used then would find a buyer on an invoice, but they returned the buyer as a block of text. Name, street address, city, country, sometimes phone or fax, all in one extracted field. For a basic comparison this was fine. For anything more nuanced, like comparing street to street, or applying a rule that says a country code mismatch matters but a street name variation does not, we needed structure inside that block of text.

Unfortunately, the custom machine learning (ML) approach was just not able to get us there. To do finer-grained reasoning TradeSpeed needed a different layer above it. That became the next tech investment and it started happening precisely as large language models (LLMs) were maturing enough to be implemented.

Read part 1 of the series
Under the hood with Gary Collyer: how TradeSpeed builds its document examination checks
2023: AI Insights and intelligence at the data extraction layer
The first generation of production-ready large language models for the challenges we were seeing in checks arrived during 2023. As much potential as they showed, we knew they were still not fully ready for check logic, so we didn't put them in charge of checks just yet. However, we found something specific they were very good at: refining the structured-but-coarse data the extraction layer was producing. The precise problem we were facing with the custom ML models.

We called these refined extractions "AI Insights". Micro-prompts running on individual extracted fields, sitting between data extraction and the check engine. An AI Insight took the buyer block from the previous era and split it cleanly into name, street, city, country, phone. It normalised dates. It interpreted phrases like "notify the applicant" and resolved them into structured data the check engine could actually compare. And critically, every AI Insight was visible and editable in TradeSpeed's UI. If the model got something wrong (unusual but no model has 100% accuracy yet), an examiner could correct it directly, and the check would re-run against the corrected interpretation.
This worked beautifully for a whole class of problems. The check engine now had structured, granular inputs to work with. Accuracy lifted across many checks with the same check logic, just with the improvement of the underlying input data points. Many of those checks today still run on AI Insights, because for what they need to do, this is the right tool.

While this new approach to checks brought huge gains, AI Insights had one clear limit: they operate on one extracted field at a time. That made them less useful for checks where reasoning had to span multiple fields, or where the right judgement could only be made on the running check itself. We wanted to bring LLM judgement inside a check, not just into the preparation layer ahead of it. That ambition shaped what came next.

2024: Generative AI extraction and check prompts, intelligence and judgement across the board
2024 was the year a great deal converged. Google's Gemini model became available and our extraction quality jumped sharply. If it was high before, we were now confident that TradeSpeed was getting the highest results across the market and industry, continuously on a 95% extraction accuracy baseline. With no prior training needed. We could suddenly handle a much wider range of documents, including the long tail of unusual document types, without training a model per type. The previous, necessary yet painful, annotation cycle we'd lived through in 2022 was almost immediately dispensable. Where we'd needed thousands of examples to train a model, now we often needed a couple, and sometimes none at all.
But these new production-ready large language models enabled even more. Alongside the data extraction lift, we introduced what we called "check prompts". Inside specific rules in the check engine, we gave the system the ability to consult an LLM at runtime for judgements and logic no static rule could pre-encode. "The credit allows any port in Europe." "The bill of lading says Antwerp." Is that compliant? The rule fires a check prompt, gets the answer, and continues. It understands that Antwerp is in Belgium, and Belgium is in Europe. The rule engine still drives the check, while the LLM consults on the parts where logic and reasoning are needed.


Across the whole platform, this remains the workhorse architecture for a large share of TradeSpeed's checks today. Extraction with Gemini, refinement with AI Insights, deterministic rules with check prompts where needed. This delivers the highest accuracy at the highest efficiency depending on what is needed for each check.
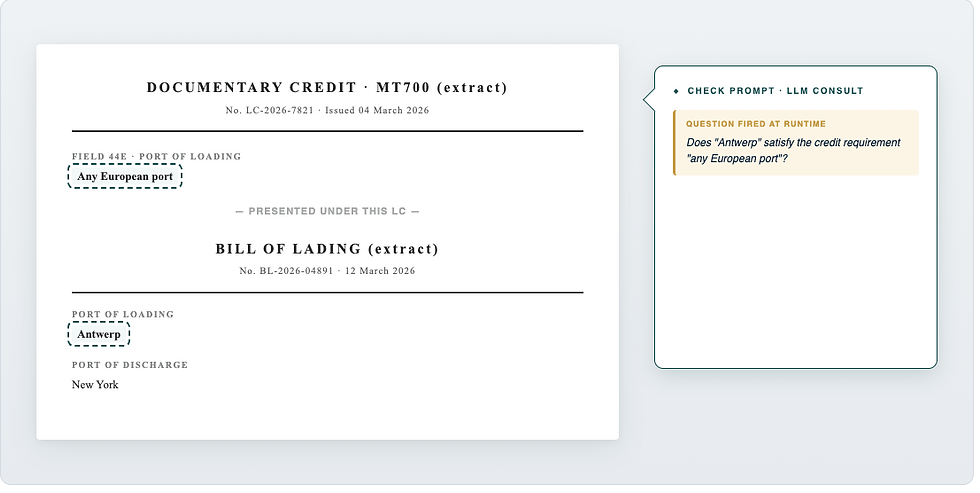
During this era, one challenge stayed open still: cross-document context. Even with the best extraction in the market, the workflow still moved through three stages: extract pieces of the document, refine those pieces, then reason on the refined pieces. For checks where the meaningful question spans multiple documents at once, feeding the model fragments was not the best shape of input. We needed full context.
"Does this quantity tie out across the invoice, the packing list, and the bill of lading?" "Does this free-text condition in field 47A actually hold up against everything else the credit says?" Those questions need full-document context, not pieces of one document at a time. Luckily, GenAI and LLM technology was concurrently evolving in a way that allowed us to address this challenge.

2025: Multimodal checks, where context is king
In 2025 we started experimenting with feeding full documents directly to vision-capable GenAI. Not just extracted text. The actual documents themselves: invoices as images, bills of lading as PDFs, the credit alongside. The model sees what an examiner sees, and it reasons across everything at once.
The principle that emerged from those experiments is the one we build new checks around today: when logic and intelligence are needed, context is king. When the model has the whole picture, it makes judgements that piece-by-piece extraction simply could not. A classic example is a quantity calculation. A bill of lading says "fifty pallets, twenty boxes per pallet, twelve units per box." A packing list says "twelve thousand units." A pure-extraction approach has to lift each number separately, label each correctly, then do arithmetic on them. A multimodal approach reads the documents together and recognises that the two figures describe the same shipment.

Arithmetic isn't the only thing that improves here. TradeSpeed's recently launched signature and stamp detection is another proof point: it identifies and verifies signatures, stamps and endorsements, asking questions like "Is this transport document signed by an entity with the capacity it claims, with the right stamps, on the right page?"
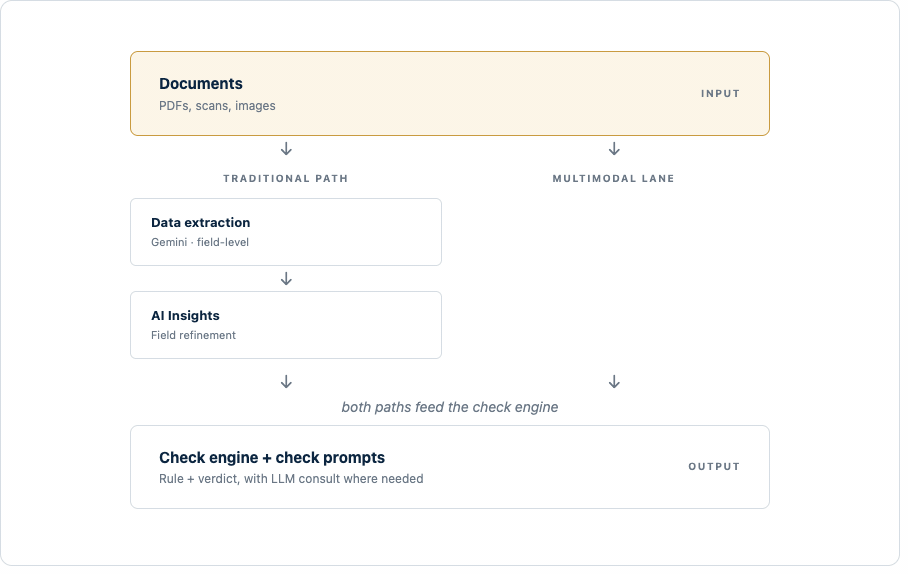
How different types of checks coexist today
These four architectural generations don't replace each other. They coexist. The right approach for any sophisticated platform to implement is the one where each job gets the right tool. In other words, TradeSpeed aims for the highest accuracy while maximising efficiency.
Many checks today run on AI Insights, and that is precisely the right choice for them. Others run on an "if/then" rule engine plus check prompts, because that combination is the best fit for the work those checks need to do. Multimodal is not always the correct replacement for the earlier layers. It is an addition to the toolkit for the checks where reading the whole document in full context unlocks something the earlier approaches couldn't yet do.
Each generation has extended what's possible without retiring what came before. That is by design. A platform that ripped out and replaced itself every couple of years would not be one banks could trust to run their operations on.
Original checks aren't frozen either. When a newer architecture meaningfully improves a check the previous layer was already handling (higher accuracy, better edge-case coverage, less manual oversight), we move that check across. The bar is the same one we hold for new checks: the new approach has to do the work better than what's currently in place.
Which is also why the architecture mix beneath the platform is a moving target. The blend we've described here today won't be the blend in one year. New technology enables new checks where they were impossible before and improves existing checks where it can.
As models improve, the mix we've described here will keep shifting: some checks running on AI Insights today have become multimodal, others are becoming fully agentic. Across four years, the direction has held: build to the frontier as it exists, keep what works, upgrade in place as better technology comes along.
What does all of this mean for examiners today?
Sitting at the examiner desk, none of this should matter. The technology underneath a check shouldn't be something a senior examiner has to keep in their head. Every check on TradeSpeed runs seamlessly: structured comparison and matching where that's enough, runtime reasoning where it isn't, full-document context where the question demands it. The examiner doesn't need to know which layer is doing the work. The promise is that the right one is, and that they can trust us on that.
A check the platform can't run with high confidence is flagged for manual review, not silently waved through. As Gary Collyer put it in last month's interview, "if there's no check, there's no examination, and that could be critical for a bank." That's why when TradeSpeed encounters a condition it can't verify with confidence, it "will indicate to the user that they need to investigate."
The job is still what it always was: examine the documents, weigh the discrepancies, analyse risks and red flags, decide what holds and what doesn't. Automating more of the manual and tedious tasks they are burdened with means more time on the decisions where their judgement actually matters, and more time building profitable customer relationships.
What comes next
The work doesn't stop here, or ever. The next step we're building toward is checks that adapt to uncertain and unseen conditions, that have the agency to define next steps or rules and expand what would be possible to check for based on static rules libraries only.
With expanded coverage for line items, multiple goods, partial shipments, and the kind of complex presentations the market has long struggled to handle automatically, this next chapter for TradeSpeed feels like a real step-change. We will share more on this soon, as the technology matures enough to be implemented with confidence.
If you'd like to see all of these checks live and how the architecture shows up in the actual examiner experience, just get in touch. We'd be glad to walk you through it.
Want to be the first to know about TradeSpeed developments?
Subscribe to our monthly spotlight list.
 | Aisling Mullins Chief Product Officer Ais is a seasoned product leader with a strong background in trade finance and technology. She has more than a decade of experience in FinTech and has held roles at the Royal Bank of Scotland, Bank of Ireland and most recently served as CPO at MonetaGo before joining Complidata. |

